Wir freuen uns sehr über die Zusammenarbeit mit den Studenten und wir möchten euch kurz vorstellen, in welchen Themengebieten wir uns besonders über eure Unterstützung freuen würden. Kommt gerne mit euren Ideen und Vorstellungen vorbei und wir suchen gemeinsam nach Möglichkeiten, wie ihr eure Abschlussarbeiten, Seminararbeiten, Forschungs- und Projektmodule bei uns erledigen könnt. Für Fragen stehen wir euch jederzeit zur Verfügung.
Differenzierbarkeit von Nachbarschaftssuche und der Earth Mover’s Distance
Im Kontext von Deep Learning und Neuronalen Netzen ist für den Trainingsprozess unerlässlich, dass der Code vollständig differenzierbar ist, um die Gradienten für die Trainingsupdates berechnen zu können. Bei zwei Teilen ist dies aktuell noch nicht so.
In vorhergegangen studentischen Arbeiten wurde eine GPU-fähige Nachbarschaftssuche und eine Lossfunktion basierend auf der Earth Mover’s Distance implementiert. Diese sind in der aktuellen Form nicht differenzierbar.
Das Ziel der Arbeit ist die Untersuchung, ob einerseits eine differenzierbare Implementierung anhand der bestehenden Modul möglich ist, oder ob andererseits in der Literatur passendere Algorithmen verfügbar sind, die es dann zu implementieren gilt.
Vorgehen:
- Einarbeitung in die Nachbarsschaftssuche und Earth Mover’s Distance
- Überprüfung der Anwendbarkeit von AD und Literaturrecherche
- Implementierung und Testung
Vorraussetzungen:
- Vorkenntnisse in Julia sind wünschenswert
- Erfahrungen mit NeuralODE und AD sind von großem Vorteil
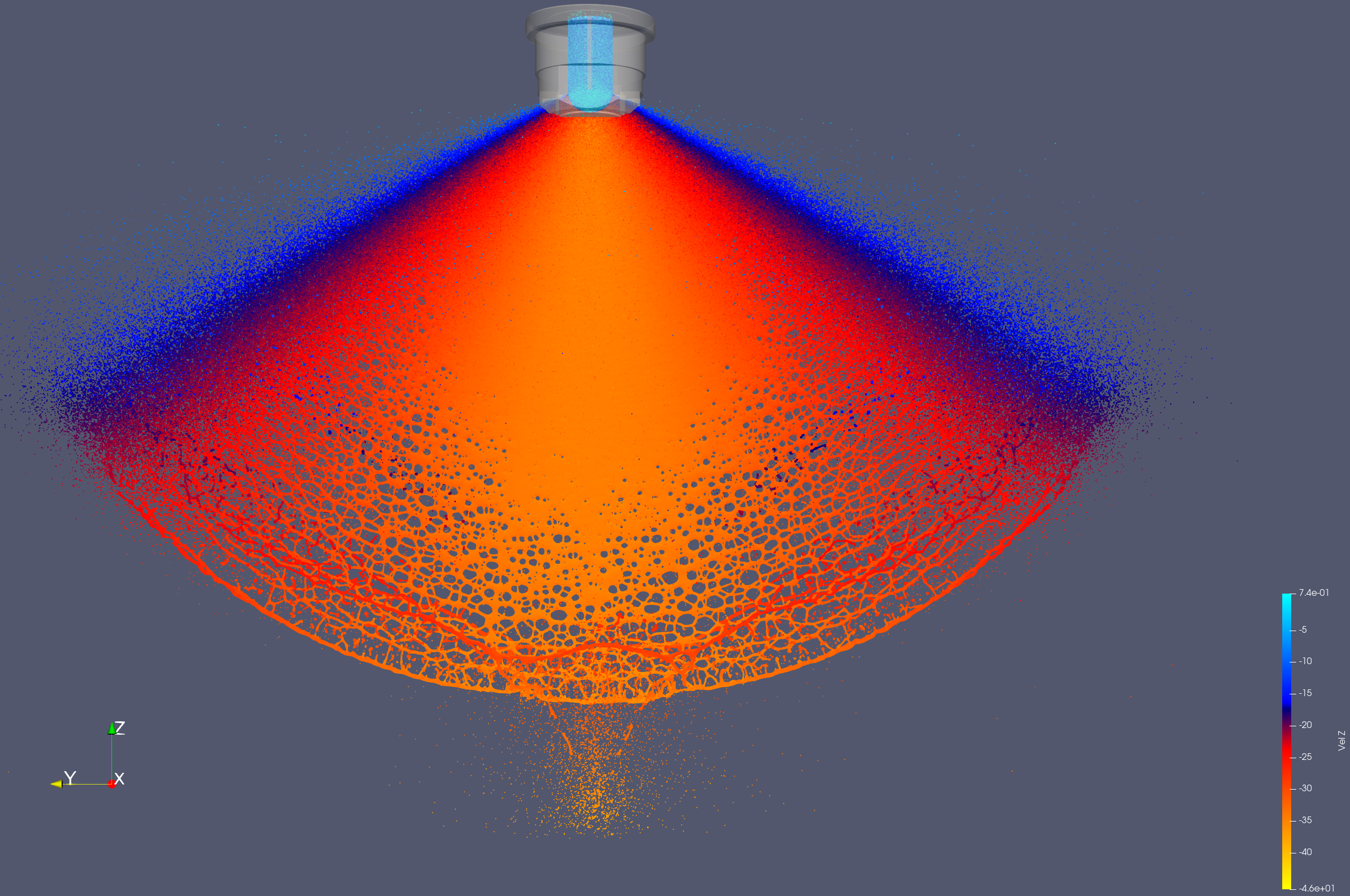
Messung von Sprühbildern von Partikelsimulationen
Diese studentische Arbeit befasst sich mit der Erfassung von Sprühbildern in Partikelsystemen.
Eine mögliche Validierung von Düsensimulationen ist die Betrachtung von Sprühbildern. Dafür wird die Masseverteilung in einem gewissen Abstand gemessen und mit realen Daten verglichen. Um dies zu erreichen werden die bereitgestellten Simulationsdaten aufbereitet, um wichtige Größen aus den Partikeldaten abzuleiten. Diesen sollen wiederum den bestehenden Daten hinzugefügt werden und in der Visualisierung ersichtlich sein.
Vorgehen:
- Recherche von wichtigen KPIs im Zusammenhang mit Oberflächenbenetzung
- Auswahl der Methoden zur Implementierung der KPIs
- Implementierung und Testung
- Einbettung in die Visualisierung
Vorraussetzungen:
- Vorkenntnisse in Julia sind wünschenswert
- Erste Erfahrungen mit Partikelsimulationen sind von Nutzen
Weiterentwicklung der Methodik von Graph Neural Networks
Graph Neural Networks (GNNs) eignen sich hervorragend als Surrogatmodelle für graphbasierte Simulationen, denen komplexe physikalische Phänomene zugrunde liegen. Durch das Lernen lokaler Zusammenhänge können sie auch bei sich ändernden Geometrien oder Topologien des Graphen weiterverwendet werden, ohne dass ein erneutes Training erforderlich ist. In dieser Arbeit soll die Methodik des in unserem Softwarepaket bestehenden GNN-Ansatzes weiterentwickelt werden, um ein schnelleres Training und eine höhere Vorhersagegenauigkeit zu ermöglichen.
Mögliche Schwerpunkte sind die Evaluation der Modellperformance bei variierenden Geometrien, die Untersuchung verschiedener Trainingsstrategien sowie die Integration zusätzlichen physikalischen Wissens.
Die Arbeit richtet sich an Studierende mit Interesse an maschinellem Lernen, der Programmiersprache Julia (oder Python, da viele Parallelen existieren) und aktueller Forschung im Bereich Scientific Machine Learning (SciML).
Reharobotik für Armfunktionstraining nach Schlaganfall

Gemeinsam mit dem Therapiezentrum Burgau wollen wir zeitnah mit der Entwicklung eines Reharoboters starten, der zur teilautomatisierten Therapie im Armfunktionstraining nach Schlaganfall eingesetzt werden soll. Der Roboter verstärkt und führt dabei die Bewegung der Patientinnen und Patienten mit Armparese (min. halbseitige Lähmung der oberen Extremitäten) und entlastet dadurch die Therapeutinnen und Therapeuten.
Thema 1
Für Medizinsysteme ist Sicherheit von höchster Bedeutung. Insbesondere bei Lähmungen sind technische Fehler in der Roboterbewegung fatal, da die Patientinnen und Patienten im Zweifel keinen Schmerz verspüren und äußern können. Dadurch besteht ein hohes Verletzungsrisiko. Darüber sind Patientinnen und Patienten häufig mit einer Spastik (schmerzhafte Verkrampfung von Muskeln) konfrontiert. Arbeitet der Roboter gegen den Widerstand der Verkrampfung kann dies zu starken Schmerzen führen.
In der Arbeit ist ein Sicherheitslayer zu implementieren, der die grundlegende Sicherheit gegen mechanische Verletzungen sicherstellt. Insbesondere soll eine Spastikerkennung implementiert werden, die eine Verkrampfung von einem aktiven Gegendruck und einer Lähmung unterscheiden kann. Dazu wird die Kraftsensorik des Tool-Flansch des Universal Robots UR10e und der daran angeschlossenen anthropomorphen Hand verwendet.
Thema 2
Der Reharoboter soll nicht nur autark mit den Patientinnen und Patienten arbeiten, sondern auch gemeinsam mit den Therapeutinnen und Therapeuten eine Therapieübung durchführen. Dadurch entsteht ein ternäres System, in dem Therapeutin, Patient und Roboter gemeinsam den Arm des Patienten kontrollieren. Ternäre Systeme sind im sogenannten Shared Control (grob: gemeinsame Regelung von technischen Systemen) nur selten vertreten. Darüber hinaus stellt ein teilgelähmter Arm kein steifes Element im System dar und unterliegt Sicherheitskriterien (s.o.).
In der Arbeit soll untersucht werden, welche Ansätze aus dem Shared Control sich eignen, das System unter Führung des menschlichen Therapeuten zu regeln. Denkbar sind bspw. Spiele (Spieltheorie), um die Interaktion zu beschreiben. Als Ausgangspunkt dient die am Prüfstand vorhandene Sensorik (Kraft/Momente, Kameras, Motion Capture) und der Universal Robots UR10e sowie vorhandene Methoden zur Schwerelosregelung.
Was wir bieten
- Einblicke in die Mensch-Roboter-Interaktion und Rehamedizin
- Lockere Arbeitsathmosphäre
- Flexible Betreuung
- Arbeiten am realen Roboter
Was du mitbringst
- Studium der Ingenieursinformatik, Medizininformatik, Informatik, oder ähnliche
- Interesse an Mensch-Roboter-Interaktion mit medizinischem Einschlag
- Vorwissen in Robotik und ROS 2 wünschenswert
Klassifikation von Griffvariaten für Roboterhände

Am Lehrstuhl für Mechatronik untersuchen wir Mensch-Roboter Interaktion in verschiedenen Anwendungsfällen. Dabei werden Roboterbewegungen per Learning from Demonstration (d.h. durch Nachahmung des Menschen durch den Roboter) angelernt. Einen zunehmend wichtigen Faktor spielen dabei für den Menschen ausgelegte Prozesse, sei es das Schraubeneindrehen in der Arbeitswelt oder Lebensmittel einräumen im Haushalt. Entsprechend gewinnen roboterhände zunehmend an Relevanz.
In dieser Arbeit sollen menschliche Bewegungen per markerless Tracking wahrgenommen werden (dazu existieren Vorarbeiten) und basierend auf dem Skelett der Hand, die vorliegenden Griffvarianten klassifiziert werden. Unsere Roboterhand (Prensilia Mia Hand) verfügt über vordefinierte Griffvarianten (z.B. Pinzetten- oder Umfassungsgriffe). Diese sollen anschließend auf die menschliche Bewegung gematched werden. Das ergebnis der Arbeit dient dann als Eingang in unsere Ansätz für das Learning from Demonstration.
Deine Aufgaben
- Erstellen eines kleinen Datensatzes verschiedener Griffvarianten mit unserem Prüfstand
- Vergleich und Auswahl von geeigneten Machine Learning Verfahren für die Klassifikation
- Validierung der Klassifikation auf dem erstellten Datensatz
Du bietest
- Studium der Ingenieursinformatik, Informatik, Medizininformatik, Mathematik oder ähnliche Studiengänge
- Interesse an Mensch-Roboter Interaktion und Roboterhänden
- (wünschenswert) Vorerfahrungen mit Machine Learning in Python
Vorhersage von Leistungsfähigkeit von Menschen durch GPT Modelle
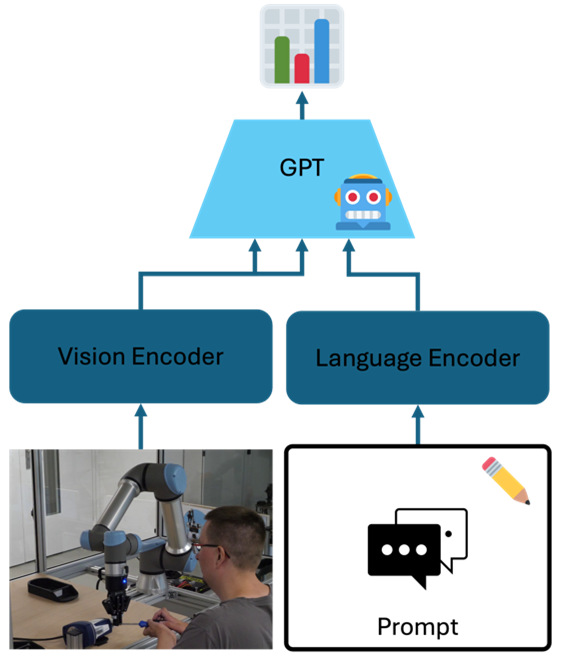
Am Lehrstuhl für Mechatronik untersuchen wir Mensch-Roboter Interaktion von einem besonderen Blickwinkel. Jeder Mensch besitzt Fähigkeiten. Diese lassen sich bereits über arbeitsmedizinische Dokumentationsverfahren bewerten. Gleichsam lassen sich Anforderungen an einen Arbeitsprozess definieren. Über den Vergleich von Fähigkeiten und Anforderungen lässt sich dann auswerten, in welchen Bereichen eine Person eingesetzt werden kann. Das ist besonders dann wichtig, wenn es sich bei den Personen um Menschen mit Behinderung oder alternde Arbeitnehmer handelt, die eben nicht in beliebigen Arbeitsprozessen eingesetzt werden können.
Um dieses Vorgehen in Mensch-Roboter-Systemen einsetzen zu können, muss der Roboter in die Lage versetzt werden, die Fähigkeiten des Menschen automatisch erfassen zu können. In dieser Arbeit soll untersucht werden, inwiefern Multimodale GPT Modelle (auch Vision Language Models genannt) verwendet werden können, um basierend auf Videodaten Vorhersagen über die Leistungsfähigkeit von Personen zu treffen. Dazu sollen verschiedene Ansätze verglichen und erweitert werden, um später Fragen bewerten zu können, wie „Kann die Person die Schraube greifen?“ oder „Kann die Person das Werkzeug bedienen?“.
Deine Aufgaben
- Erstellen eines kleinen Datensatzes mit unserem Prüfstand
- Benchmark bestehender GPT Modelle im Hinblick auf die Vorhersagequalität der Leistungsfähigkeit von Menschen
- Einsatz von Prompt Engineering Techniken, sowie Erweiterung und Fein-Tuning der Modelle
- Anbindung der Methodik an unseren Prüfstand
Du bietest
- Studium der Ingenieursinformatik, Informatik, Medizininformatik, Mathematik oder ähnliche Studiengänge
- Interesse an Mensch-Roboter Teaming und Ergonomie
- Interesse an Maschinellem Lernen
- Gute Deutschkenntnisse in Wort und Schrift
Die Arbeit wird von mir zusammen mit Damian Boborzi betreut.
Empirical evaluation of training methods for Balanced Neural ODEs
Die Energiewende stellt uns vor die Herausforderung, Energie effizient zu nutzen und flexibel auf die schwankende Erzeugung aus erneuerbaren Quellen zu reagieren. Hochaufgelöste Simulationen physikalischer Systeme (z. B. CFD) sind für die Optimierung dieser Prozesse unverzichtbar – aber oft zu rechenintensiv für den praktischen Einsatz in iterativen Optimierungen. Die Lösung: Model Order Reduction – vereinfachte Ersatzmodelle, die schnell und zuverlässig einsetzbar sind.
Hier setzt das spannende Feld des Scientific Machine Learning an: Statt mühsamer manueller Vereinfachungen ermöglichen Methoden wie Variational Autoencoder (VAE) kombiniert mit Neural Ordinary Differential Equations (Neural ODEs) die automatisierte Ableitung dynamischer Ersatzmodelle. In diesem Projekt untersuchst du das Training solcher Modelle – speziell sogenannter Balanced Neural ODEs, die vielseitig einsetzbar sind, z. B. bei Wärmepumpen oder Kraftwerken.
Ziel der Arbeit ist es, empirisch zu analysieren, wie man Neural ODEs und Balanced Neural ODEs effizient trainieren kann. Dabei spielst du an der Schnittstelle zwischen Machine Learning und numerischer Simulation – mit Herausforderungen wie Backpropagation und ODE-Lösern zum Neural ODE Training. Wenn du neugierig auf moderne Modellierung, Machine Learning und echte Anwendungsrelevanz bist, ist das dein Projekt! Komm gerne auf mich zu, um mehr zu erfahren.
Software für Scientific Machine Learning (SciML)
Wenn mächtige, aber schwerfällige Simulationsmodelle aus der Industrie und nagelneue, flinke Methoden aus dem maschinellen Lernen zusammen kommen, dann kollidideren Welten - dank FMI.jl und FMIFlux.jl bekommt man davon aber (fast) nichts mit. Damit das so bleibt - und wir im Idealfall das “fast” im vorhergehenden Satz bald komplett streichen können - brauchen wir Nachwuchs-Wissenschaftler (HiWi / Forschungsmodul / Projektmodul), die an unseren Open-Source-Paketen FMI.jl und FMIFlux.jl mitwirken wollen. Wenn du sogar schon erste Erfahrungen mit der Entwicklung von Softwarebibliotheken und/oder GitHub hast und diese weiter ausbauen möchtest, dann bist du hier gold-richtig.
Beispielsweise stehen folgende Aufgaben-Pakete bereit:
- Integration von Functional Mock-Up Units (FMUs) über FMI.jl in das ModelingToolkit.jl (MTK)
- Implementierung von Scheduled Execution in FMI.jl
- Implementierung von System Structure and Parameterization in FMI.jl
- …
Vergleich von Optimal-Control-Toolchains in Julia
Am Lehrstuhl für Mechatronik beschäftigen wir uns regelmäßig mit Optimal-Control-Problemen, insbesondere im Kontext modellprädiktiver Regelung (MPC). Für die Umsetzung solcher Algorithmen ist die Programmiersprache Julia besonders interessant. Es existieren bereits mehrere Pakete und Workflows zur Lösung von Optimal-Control-Problemen, z. B.:
Ziel der Arbeit ist es, einen systematischen Überblick über bestehende Julia-Toolchains zur Lösung von Optimal-Control- und MPC-Problemen zu gewinnen. Dazu sollen relevante Pakete identifiziert, in ihrer Funktionsweise analysiert und hinsichtlich ausgewählter Kriterien verglichen werden.
Mögliche Fragestellungen sind u. a.:
- Entwicklungsstand und Community-Aktivität
- Funktionsumfang und unterstützte Features
- Eignung für echtzeitfähige Anwendungen
- Kompatibilität mit DGL-Lösern (DifferentialEquations.jl)
- Anbindung an Optimierungs-Backends wie Optim.jl, Optimisers.jl
- Unterstützung verschiedener Modellarten (z. B. neuronale Netze, FMUs, ModelingToolkit.jl,…)
- Differenzierbarkeit mit verschiedenen AD-Backends (ForwardDiff.jl, Zygote.jl, Enzyme.jl,…)
- Vergleich mit MPC-Toolboxen anderer Sprachen, z. B. do-mpc, MATLABs Model Predictive Control Toolbox
- Umsetzung von MPC-Strategien mit FMUs über FMI.jl
Der Umfang der Arbeit kann flexibel gestaltet werden und richtet sich nach dem gewählten Format. Einzelne Teilaspekte wie MPC mit FMUs oder Differenzierbarkeit von OC-Formulierungen lassen sich auch im Rahmen einer vertieften Abschlussarbeit gesondert bearbeiten.
SciML against AML

Jeder sechste Mensch stirbt laut WHO an Krebs. Dem gegenüber steht der stetige wissenschalftliche Fortschritt auf dem Gebiet der Krebsforschung, sodass viele Krebsarten geheilt werden können wenn sie frühzeitig erkannt und effektiv behandelt werden.
Der Lehrstuhl Mechatronik startet 2025 zusammen mit dem Universitätsklinikum Augsburg Forschung im Bereich der Akuten myeloischen Leukämie (AML). Wir untersuchen, in wie weit wir unseren etablierten Methoden aus dem Scientific Machine Learning (SciML) auch für die Vorhersage des Krankheitsverlaufs bei AML in Behandlung einsetzen können - und idealwerweise sogar neue Erkenntnisse zu dieser Krankheit generieren können.
Bei dieser herausfordernden Forschungsaufgabe kommen verschiedene fachliche Schwerpunkte zusammen, sowohl aus der Medizin selbst, als auch aus dem maschinellen Lernen. Gute Forschung beginnt mit dem Erfassen des aktuellen, internationalen Forschungsstandes. Einen wesentlichen Teil zu diesem ersten Schritt trägst du mit deiner Seminararbeit bei.
Datengetriebene Model Predictive Control
Du hast Kenntnisse in der Regelungstechnik und Interesse an der Integration von KI-Methoden in die Regelungs-/Steuerungsmethoden?
Model Predictive Control ist eine Reglungstechnik, bei der ein System – wie z. B. ein Auto, eine Drohne oder eine Industrieanlage – in die Zukunft “blickt”, um zu entscheiden, was es als Nächstes tun soll. MPC nutzt ein Modell, um vorherzusagen, wie sich das System entwickeln wird. Es plant also im Voraus, indem es berechnet, welche Aktionen (wie Beschleunigen, Bremsen oder Lenken) am besten geeignet sind, um ein Ziel zu erreichen, ohne dabei Einschränkungen zu verletzen (wie z. B. eine maximale Geschwindigkeit oder bestimmte Sicherheitsgrenzen).
Was wir bieten
- Einblicke in den Stand der Technik von probabilistischem Deep Learning
- Einführung von Jax
- Flexible Betreuung
Was du mitbringst
- Vorkenntnisse in Regelungstechnik, Deep Learning, Reinforcement Learning
- Programmierfähigkeit in Python
Datengetriebene Beobachter
Du hast Kenntnisse in der Regelungstechnik und Interesse an der Integration von KI-Methoden in die Regelungs-/Steuerungsmethoden?
In der Regelungstechnik ist ein Beobachter ein System, das aus bekannten Eingangsgrößen (z.B. Stellgrößen oder messbaren Störgrößen) und Ausgangsgrößen (Messgrößen) eines beobachteten Bezugssystems nicht messbare Größen (Zustände) rekonstruiert. Für nichtlineare Systeme mit teilweiser unbekannter Dynamik sind traditionelle Beobachter nur bedingt einsetzbar. Unser Ziel ist es, einen datengesteuerten Beobachter zu entwerfen, der nicht messbare Zustände aus Systemeingaben und -ausgaben lernen kann.
Was wir bieten
- Einblicke in den Stand der Technik von probabilistischem Deep Learning
- Einführung von Jax
- Flexible Betreuung
Was du mitbringst
- Vorkenntnisse in Regelungstechnik, Deep Learning
- Programmierfähigkeit in Python
Weiterentwicklung unserer Softwarepakete für Graph Neural Networks
Die Programmiersprache Julia wächst aktuell stark in ihrer Anwendung sowohl in der Forschung als auch in der Industrie bei großen Unternehmen wie beispielsweise ASML und Bosch. Dabei arbeitet unser Lehrstuhl aktiv an der (Weiter-)entwicklung unser aktuellen Softwarepakete für Julia, besonders im Bereich Graph Neural Networks. Dabei gibt es immer aktuelle Themen die in Angriff genommen werden können um das Paket und die Sprache voranzutreiben.
Dies beinhaltet:
- Entwicklung neuer Funktionen der Pakete
- Mitwirken an Core-Paketen von Julia
- Instandhaltung der aktuellen Software
Konditionierung von Diffusion Modellen
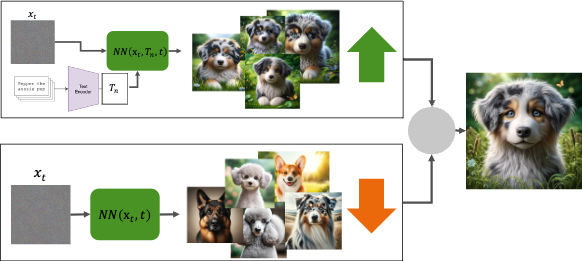
Du findest generative Modelle wie Stable Diffusion oder DALL-E, die anhand von Text detailreiche Bilder erzeugen können, spannend und hast Interesse, dich in aktuelle Machine-Learning-Themen einzuarbeiten?
In dieser Arbeit hast du die Möglichkeit, Methoden wie Stable Diffusion und SV3D genauer kennenzulernen. Stable Diffusion ermöglicht es, Bilder anhand von Text oder anderen Vorgaben zu erzeugen. Bei der Methode SV3D wird ein Bild als Vorgabe verwendet, um mehrere Bilder zu generieren, die das Objekt aus verschiedenen Perspektiven zeigen. Mithilfe dieser Perspektiven können anschließend 3D-Objekte erzeugt werden. In der Arbeit sollen Möglichkeiten untersucht werden, wie Diffsuion Modelle auf andere Eingaben, wie zum Beispiel Zeichnungen, konditioniert werden können und wie sich diese Eingaben auf die Generierung auswirken. Abhängig von der Art der Arbeit können verschiedene Ansätze untersucht werden.
Fine-tuning von Large Reconstruction Models für die 3D Objektgenerierung
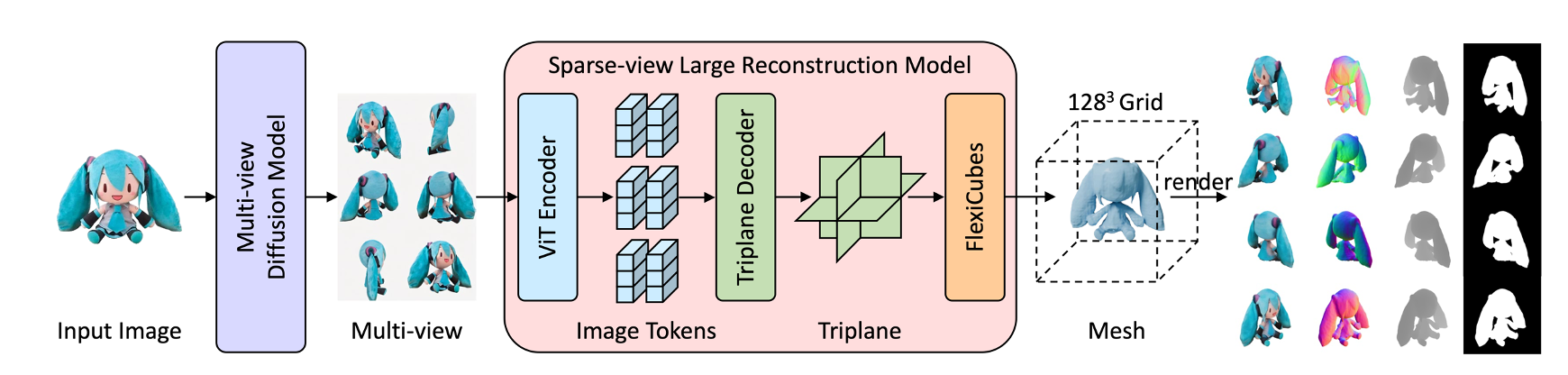
Kann man per Knopfdruck 3D-Objekte erzeugen? Generative Modelle wie Stable Diffusion oder DALL-E können bereits beeindruckende Bilder anhand einer Beschreibung auf Knopfdruck erzeugen. Das wäre auch für 3D-Objekte interessant, und tatsächlich lassen sich Methoden der Bildgenerierung auch zur Erzeugung von 3D-Objekten nutzen. Allerdings sind die Ergebnisse oft noch nicht so überzeugend wie im Bildbereich und haben häufig eine lange Rechenzeit.
Large Reconstruction Models (zum Beispiel InstantMesh) sollen vor allem das Problem der langen Rechenzeit lösen, indem ein großes Transformermodell darauf trainiert wird, in einem Durchgang direkt ein 3D-Modell zu erzeugen.
Aus dem Bildbereich kennt man verschiedene Methoden, um große generative Modelle durch Fine-Tuning anzupassen, um einen bestimmten Stil oder eine bestimmte Art von Bildern zu erzeugen. Ähnlich soll in dieser Arbeit untersucht werden, wie ein Large Reconstruction Model mithilfe von Fine-Tuning angepasst werden könnte, um Objekte aus einer bestimmten Domäne, wie beispielsweise Fahrzeuge, besser generieren zu können.