Wir freuen uns sehr über die Zusammenarbeit mit den Studenten und wir möchten euch kurz vorstellen, in welchen Themengebieten wir uns besonders über eure Unterstützung freuen würden. Kommt gerne mit euren Ideen und Vorstellungen vorbei und wir suchen gemeinsam nach Möglichkeiten, wie ihr eure Abschlussarbeiten, Seminararbeiten, Forschungs- und Projektmodule bei uns erledigen könnt. Für Fragen stehen wir euch jederzeit zur Verfügung.
Differenzierbarkeit von Nachbarschaftssuche und der Earth Mover’s Distance
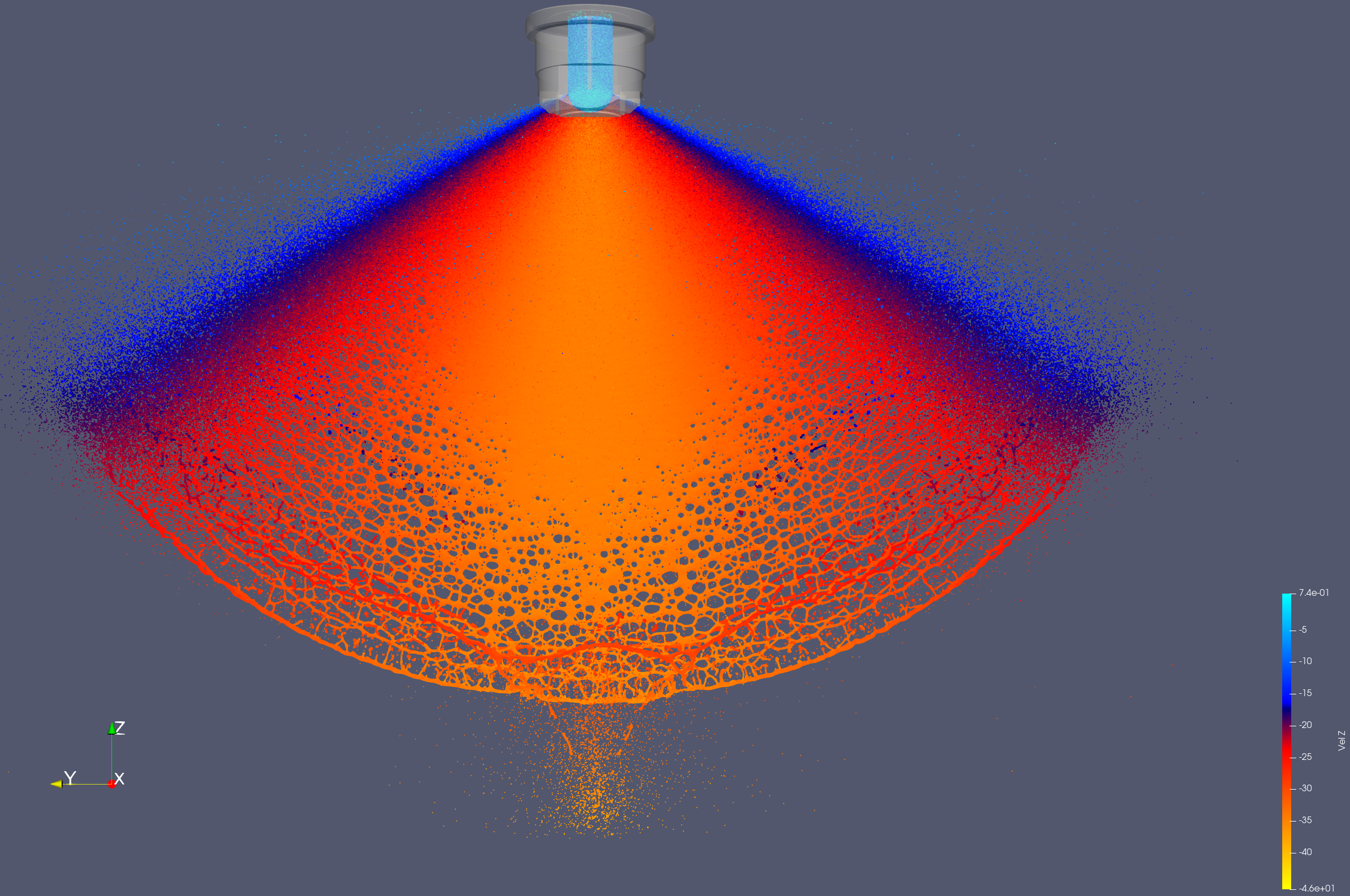
Im Kontext von Deep Learning und Neuronalen Netzen ist für den Trainingsprozess unerlässlich, dass der Code vollständig differenzierbar ist, um die Gradienten für die Trainingsupdates berechnen zu können. Bei zwei Teilen ist dies aktuell noch nicht so.
In vorhergegangen studentischen Arbeiten wurde eine GPU-fähige Nachbarschaftssuche und eine Lossfunktion basierend auf der Earth Mover’s Distance implementiert. Diese sind in der aktuellen Form nicht differenzierbar.
Das Ziel der Arbeit ist die Untersuchung, ob einerseits eine differenzierbare Implementierung anhand der bestehenden Modul möglich ist, oder ob andererseits in der Literatur passendere Algorithmen verfügbar sind, die es dann zu implementieren gilt.
Vorgehen:
- Einarbeitung in die Nachbarsschaftssuche und Earth Mover’s Distance
- Überprüfung der Anwendbarkeit von AD und Literaturrecherche
- Implementierung und Testung
Vorraussetzungen:
- Vorkenntnisse in Julia sind wünschenswert
- Erfahrungen mit NeuralODE und AD sind von großem Vorteil
Messung von Sprühbildern von Partikelsimulationen
Diese studentische Arbeit befasst sich mit der Erfassung von Sprühbildern in Partikelsystemen.
Eine mögliche Validierung von Düsensimulationen ist die Betrachtung von Sprühbildern. Dafür wird die Masseverteilung in einem gewissen Abstand gemessen und mit realen Daten verglichen. Um dies zu erreichen werden die bereitgestellten Simulationsdaten aufbereitet, um wichtige Größen aus den Partikeldaten abzuleiten. Diesen sollen wiederum den bestehenden Daten hinzugefügt werden und in der Visualisierung ersichtlich sein.
Vorgehen:
- Recherche von wichtigen KPIs im Zusammenhang mit Oberflächenbenetzung
- Auswahl der Methoden zur Implementierung der KPIs
- Implementierung und Testung
- Einbettung in die Visualisierung
Vorraussetzungen:
- Vorkenntnisse in Julia sind wünschenswert
- Erste Erfahrungen mit Partikelsimulationen sind von Nutzen
Software für Scientific Machine Learning (SciML)
Wenn mächtige, aber schwerfällige Simulationsmodelle aus der Industrie und nagelneue, flinke Methoden aus dem maschinellen Lernen zusammen kommen, dann kollidideren Welten - dank FMI.jl und FMIFlux.jl bekommt man davon aber (fast) nichts mit. Damit das so bleibt - und wir im Idealfall das “fast” im vorhergehenden Satz bald komplett streichen können - brauchen wir Nachwuchs-Wissenschaftler (HiWi / Forschungsmodul / Projektmodul), die an unseren Open-Source-Paketen FMI.jl und FMIFlux.jl mitwirken wollen. Wenn du sogar schon erste Erfahrungen mit der Entwicklung von Softwarebibliotheken und/oder GitHub hast und diese weiter ausbauen möchtest, dann bist du hier gold-richtig.
Beispielsweise stehen folgende Aufgaben-Pakete bereit:
- Integration von Functional Mock-Up Units (FMUs) über FMI.jl in das ModelingToolkit.jl (MTK)
- Implementierung von Scheduled Execution in FMI.jl
- Implementierung von System Structure and Parameterization in FMI.jl
- …